FlashMLA:DeepSeek发布的高效的MLA解码内核,优化了变长序列的处理服务
作者:啊哈哈哈 来源:08论坛 时间:2025-03-12 09:34:34
FlashMLA是什么?
FlashMLA是DeepSeek在2025年2月24日推出的一款针对NVIDIA Hopper架构GPU(如H800)优化的MLA(Multi-Head Latent Attention)解码内核,特别优化了变长序列的处理服务。

FlashMLA的主要特性:
BF16支持:FlashMLA支持BF16(Bfloat16)数据类型,这使得它在计算和内存使用上更加高效。
分页KV缓存:通过分页机制管理键值(KV)缓存,块大小为64,这使得它能够高效处理大规模序列。
高性能:FlashMLA的内存带宽可达3000 GB/s(在内存瓶颈场景下),计算性能可达580 TFLOPS(在计算瓶颈场景下,基于BF16数据类型)。
FlashMLA的技术背景:
FlashMLA的出现是为了解决大型语言模型在推理过程中面临的计算和内存瓶颈问题。传统的多头注意力机制(MHA)在处理长序列时,需要大量的内存来存储键值对(KV)缓存,这限制了模型在有限硬件资源上的部署。MLA通过引入潜在注意力机制,减少了KV缓存的大小,同时保持了模型的性能。
FlashMLA的应用场景:
FlashMLA特别适用于需要高效解码的自然语言处理(NLP)任务,如大语言模型(LLM)的推理。它针对变长序列进行了优化,并在实际生产环境中经过了验证,特别适合高性能计算需求。

FlashMLA的技术实现
低秩压缩:MLA通过低秩矩阵分解实现KV缓存的有效压缩,减少了内存占用。
KV缓存优化:优化KV缓存机制,显著降低了硬件资源需求,从而降低了推理成本。
并行解码:引入并行解码机制,允许同时处理多个token,显著提升推理速度。
FlashMLA的性能提升
采用FlashMLA后,DeepSeek在自然语言处理任务中的准确率提升了约5%,推理速度提高了20%,计算资源消耗降低了15%。这些改进使得DeepSeek在实时交互场景(如对话ai、实时翻译)中表现更优。
FlashMLA安装使用
环境要求:
Hopper 架构 GPU(如 NVIDIA A100)
CUDA 12.3 及以上版本
PyTorch 2.0 及以上版本
1. 首先,你需要安装 FlashMLA 库。你可以通过以下命令进行安装:
gitclonehttps://github.com/deepseek-ai/FlashMLA.gitcdFlashMLApythonsetup.pyinstall或者如果你已经克隆了仓库并且想要重新构建:
pythonsetup.pyclean--all&&pythonsetup.pybuild_ext--inplace2. 获取 MLA 元数据
在使用 FlashMLA 之前,你需要获取 MLA 的元数据。这通常涉及准备输入张量和其他必要的参数。
fromflash_mlaimportget_mla_metadata,flash_mla_with_kvcache#假设你已经有了cache_seqlens和其他相关变量cache_seqlens=[...]#每个序列的长度列表s_q=...#查询维度h_q=...#头数量h_kv=...#键值头数量tile_scheduler_metadata,num_splits=get_mla_metadata(cache_seqlens,s_q*h_q//h_kv,h_kv)3. 执行 MLA 解码
接下来,你可以执行 MLA 解码操作。假设你已经有查询矩阵 q_i、键值缓存 kvcache_i、块表 block_table 等必要组件。
dv=...#输出维度foriinrange(num_layers):#循环遍历每一层o_i,lse_i=flash_mla_with_kvcache(q_i[i],#当前层的查询矩阵kvcache_i[i],#当前层的键值缓存block_table,#块表cache_seqlens,#缓存序列长度dv,#输出维度tile_scheduler_metadata,#MLA元数据num_splits,#划分数目causal=True#是否因果掩码)#继续处理输出结果o_i和lse_iFlashMLA github:https://github.com/deepseek-ai/FlashMLA
更多资讯



热门文章
推荐对话
换一换


























- 人气排行
- 1 FlashMLA:DeepSeek发布的高效的MLA解码内核,优化了变长序列的处理服务
- 2 被老板追着夸的PPT,全靠这4个DeepSeek隐藏指令模板!
- 3 用DeepSeek+美间AI创意PPT,小白都能做出百万级PPT方案
- 4 DeepSeek开源周第二天开源项目:Deepep
- 5 Anthropic推出Claude Code:具备代码搜索、自动修改、测试、GitHub集成等功能
- 6 埃隆·马斯克的xAI Grok发布新Logo,非常惊艳!
- 7 阿里巴巴正式开源通义万相Wan2.1视频生成AI模型
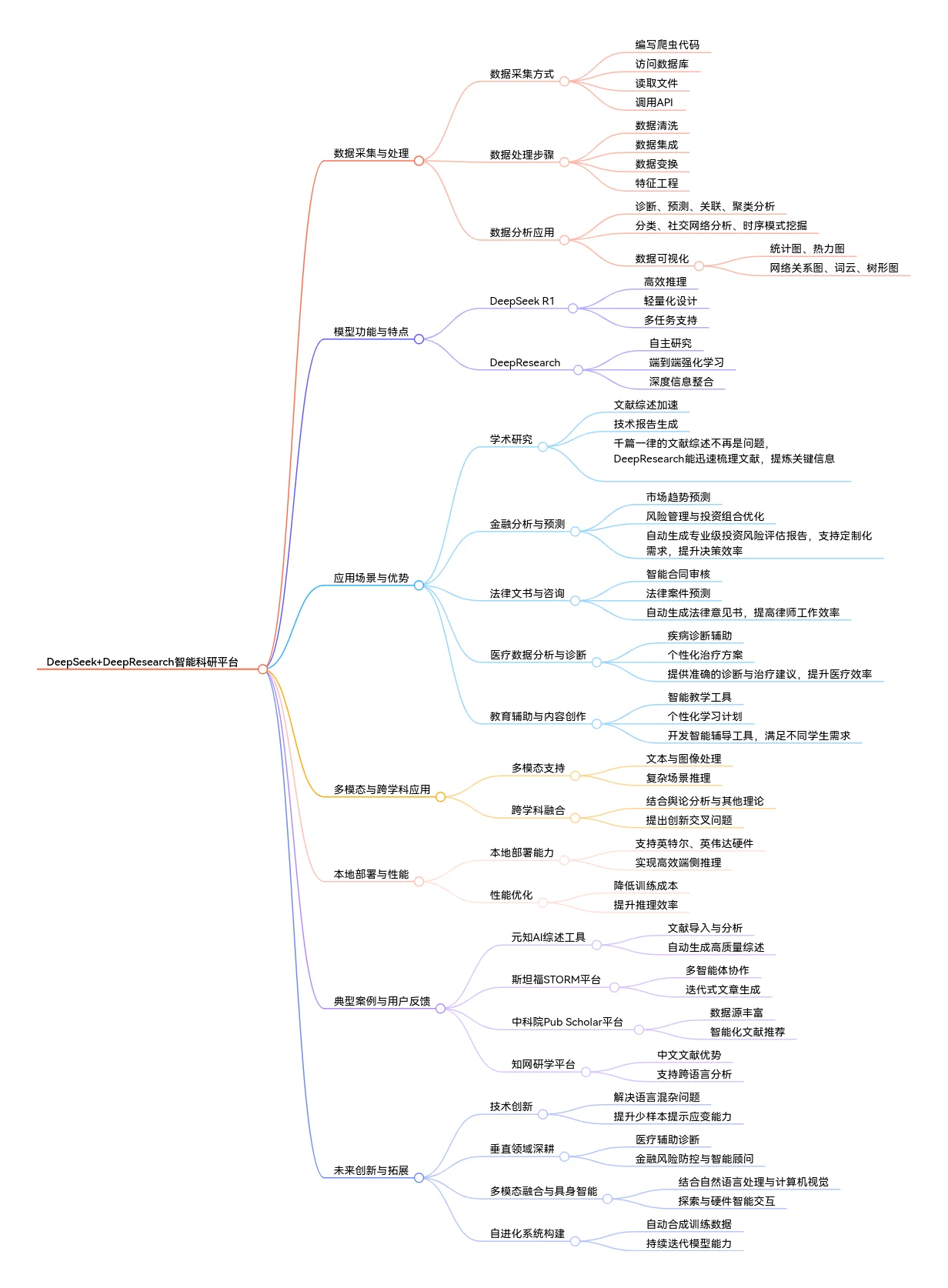
- 8 清华大学《DeepSeek + DeepResearch让科研像聊天一样简单》PDF直接免费下载,没有套路
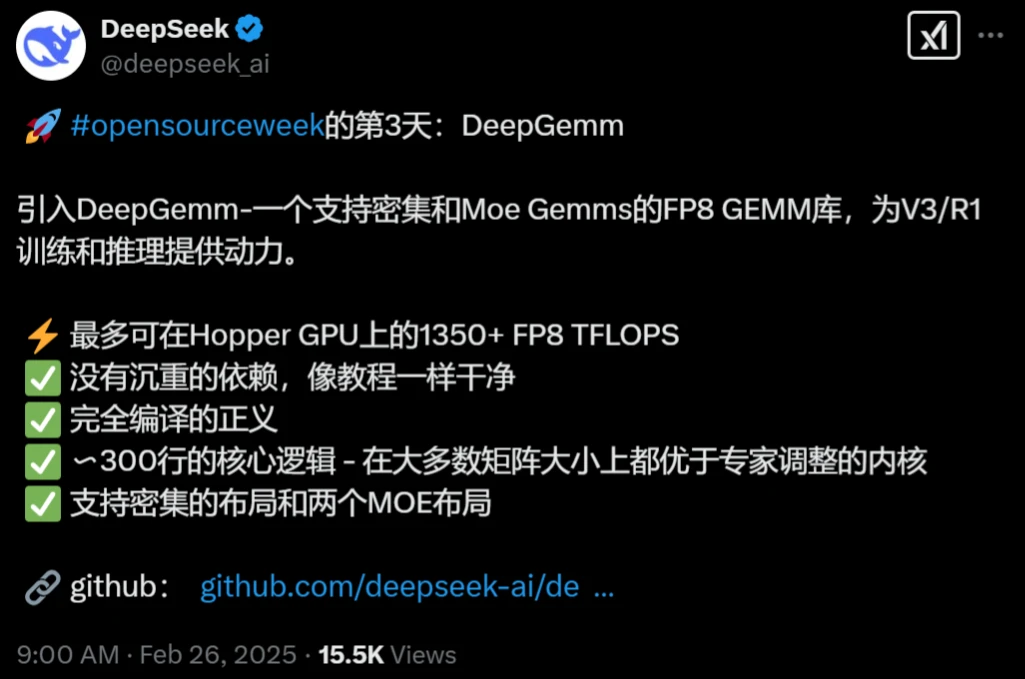
- 9 DeepSeek开源周第三天开源项目:DeepGemm
- 10 如何用DeepSeek和即梦AI、可灵AI生成“快来惹毛我”毛绒玩偶风格视频