DeepSeek开源周第五天开源项目:3FS,高性能分布式文件系统。
作者:啊哈哈哈 来源:08论坛 时间:2025-03-10 16:29:26
这边GPT4.5刚发布,这边DeepSeek开源周进入到第五天开源的项目,最后一天的开源项目是:3FS(Fire-Flyer File System)。
3FS(Fire-Flyer File System)是什么?
3FS(Fire-Flyer File System)是DeepSeek自研的高性能分布式文件系统,专为解决ai训练和推理工作负载的挑战而设计。

3FS的特征
高性能:
利用现代SSD和RDMA网络,提供高吞吐量和低延迟的数据访问。
结合数千个SSD的吞吐量和数百个存储节点的网络带宽,使应用能够以无关地域的方式访问存储资源。
强一致性:
通过实现链式复制与分配查询(CRAQ),确保强一致性,使得应用代码更简洁且易于推理。
文件接口:
采用无状态元数据服务,背后支持事务型键值存储(如FoundationDB)。
熟悉的文件接口,无需学习新的存储API。
多样化工作负载支持:
数据准备:将数据分析管道的输出组织成层次化目录结构,有效管理大量中间输出。
数据加载器:通过支持跨计算节点随机访问训练样本,消除预读取或数据洗牌的需求。
检查点:支持大规模训练的高吞吐量并行检查点。
推理KV缓存:提供一种基于成本效益的替代方案,替代DRAM缓存,提供更高吞吐量并大大提高容量。
存算分离:
数据存储服务与计算节点分离,专门用于存储模型训练需要用到的样本数据。
每个存储服务节点有16张各15TB的SSD硬盘和2张高速网卡,读取性能强劲,网络带宽强大,读写带宽:7.0TB/秒。
自研通信工具:
如hfreduce,优化多卡并行通信,替代英伟达的NCCL,减少PCIe流量和计算开销。
专用数据格式FFRecord:
通过合并多个小文件,减少了训练时打开大量小文件的开销。
通过样本文件的偏移量提升随机批量读取性能。
3FS的应用
AI训练和推理:
3FS专为AI训练和推理工作负载设计,能够显著提升这些任务的效率。
通过高性能和强一致性,3FS支持大规模模型训练和高吞吐量推理。
数据准备和加载:
3FS的数据准备和加载器功能使得处理大量数据变得更加高效,减少了预读取和数据洗牌的需求。
检查点和推理缓存:
3FS支持高吞吐量的并行检查点,确保训练过程的稳定性和容错性。
推理KV缓存提供了基于成本效益的替代方案,提高了推理吞吐量和容量。
3FS的使用
安装和配置:
3FS可以通过GitHub上的开源项目进行安装和配置。
数据格式转换:
使用FFRecord格式进行数据存储和加载,需要将样本数据转换成FFRecord格式。
提供了FFRecord转换工具,方便用户进行数据格式转换。
与PyTorch集成:
3FS适配了PyTorch的Dataset和Dataloader接口,可以非常方便地加载数据并发起训练。
GitHub项目地址:https://github.com/deepseek-ai/3FS
前四天开源项目回顾
第一天:FlashMLA,针对NVIDIA Hopper GPU的高效解码内核,优化了多头潜在注意力(MLA)的性能,显著提升了AI工具在内容创作中的响应速度。
第二天:DeepeEP,首个用于混合专家模型(MoE)训练和推理的开源通信库,优化了大规模分布式训练的通信效率,降低了延迟。
第三天:DeepGEMM,支持稠密和MoE模型的FP8计算库,专为NVIDIA Hopper架构GPU设计,显著提高了计算效率和硬件利用率。
第四天:DualPipe,一种双向流水线并行算法,旨在优化V3/R1模型训练中的计算和通信重叠。EPLB,一个专家并行负载均衡器,专门用于解决大规模AI模型中专家并行任务的负载不均衡问题。
更多资讯

热门文章
推荐对话
换一换


























- 人气排行
- 1 DeepSeek开源周第五天开源项目:3FS,高性能分布式文件系统。
- 2 文生图模型Ideogram 2A:更快的生成速度和更低的成本
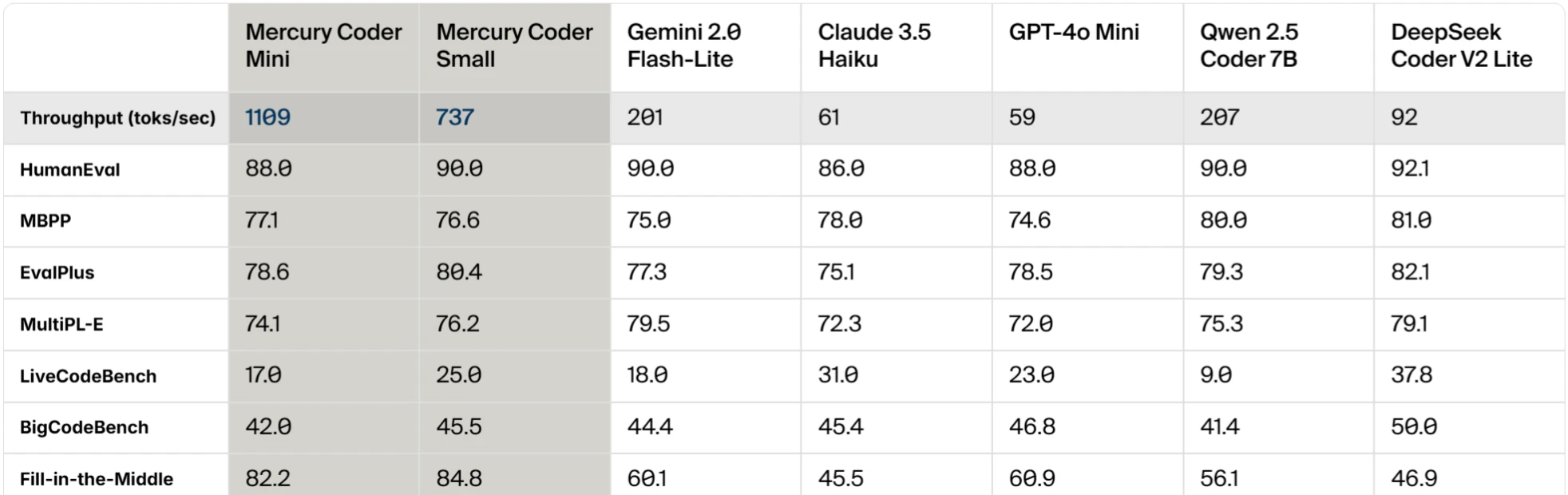
- 3 Mercury:首个商用级别扩散大型语言模型(dLLM)
- 4 BiliBili ShadowReplay:哔哩哔哩直播切片和投稿工具
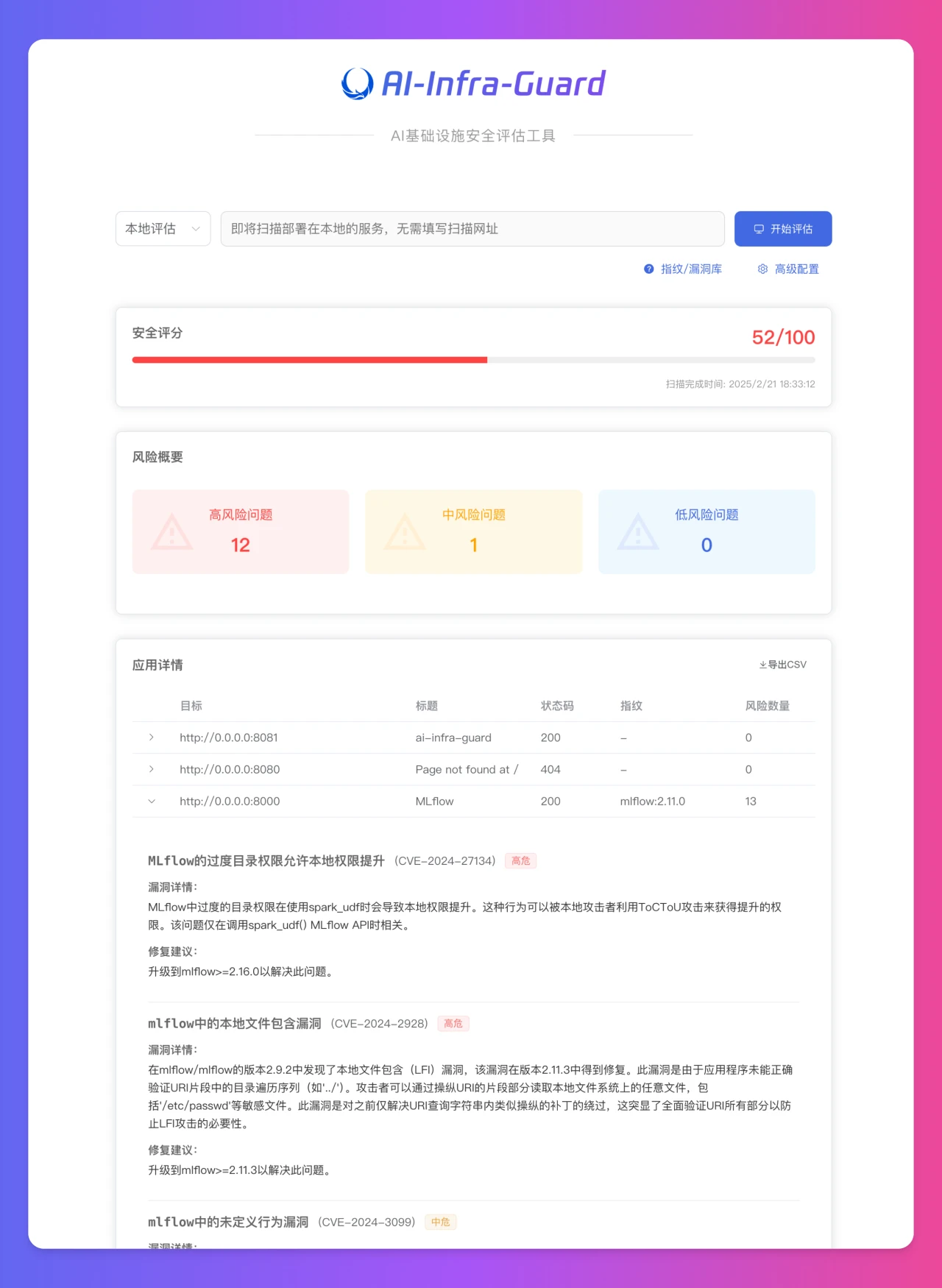
- 5 AI-Infra-Guard:腾讯开源的一个AI基础设施安全评估工具,可一键检测AI系统的潜在安全风险
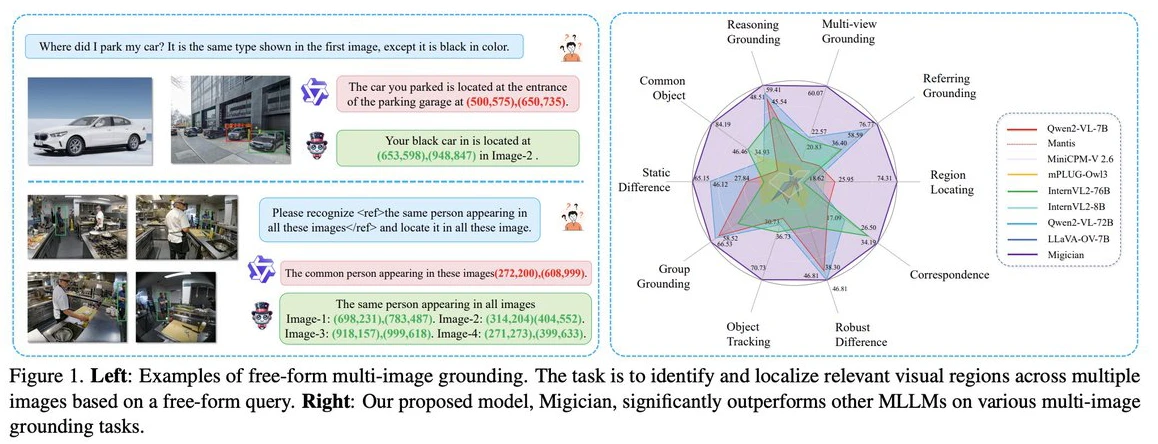
- 6 Migician:清华大学等团队出的解决复杂场景下的多图像目标定位问题的多模态模型
- 7 Mp-Vx-insight:一键获取微信公众号文章的封面图、采集文章内容
- 8 DeepSeek开源周第六天开源项目:DeepSeek-V3/R1推理系统,成本利润率高达545%
- 9 CSM:Sesame公司的语音合成模型,如同与真人交流
- 10 Leffa:Meta AI开源的用于可控人物图像生成的工具,适用于虚拟试穿。